
What are “Transformers” (Introduced by Google)
Introduction of GPT (Generative Pre-training Transformer)
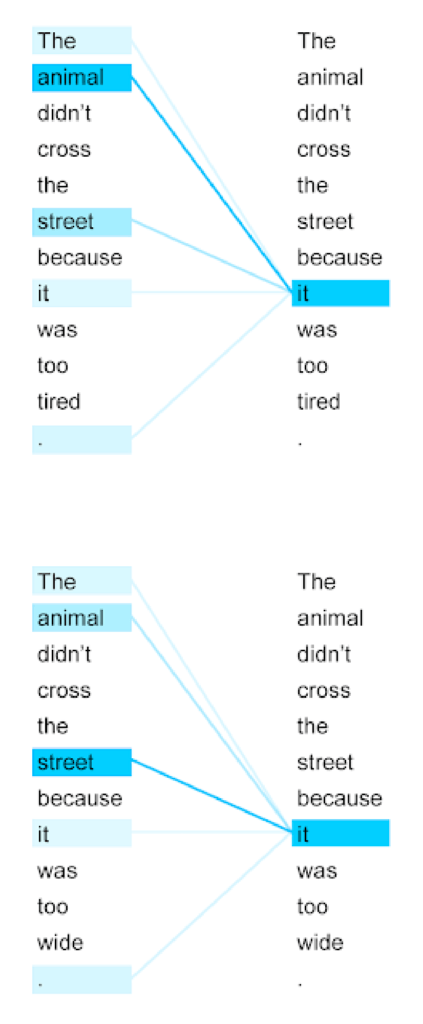
Learning Mechanism
Pre-Training
Fine Tuning
Capabilities
Conclusion

- Transformer model designed for natural language processing tasks
- 117 million parameters
- 1.5 billion parameters
- Trained on a massive corpus of text from the internet, consisting of 8 million web pages (40GB)
- A massive 175 billion parameters
- Trained on a diverse range of internet text
- Demonstrated remarkable capabilities in natural language processing tasks, including language translation, question-answering, and text completion
- Multimodal model (accepting image and text inputs, emitting text outputs)
Figure 2: Evolution of Chat GPT Large Language Model.
Future of GPT:
Looking ahead, we can anticipate that future GPT models will continue to improve upon previous generations by incorporating new features, such as multimodal data inputs that allow for a combination of image and text (which has been introduced by GPT-4 at the time of writing this article). However, as the complexity of these models increases, the training process becomes more resource-intensive, requiring large amounts of energy and infrastructure. Addressing these concerns will be critical for the continued development of GPT technology, as we seek to harness the full potential of this powerful tool for a wide range of applications, from customer service chatbots to automated writing assistants.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. http://arxiv.org/abs/1706.03762